TCP
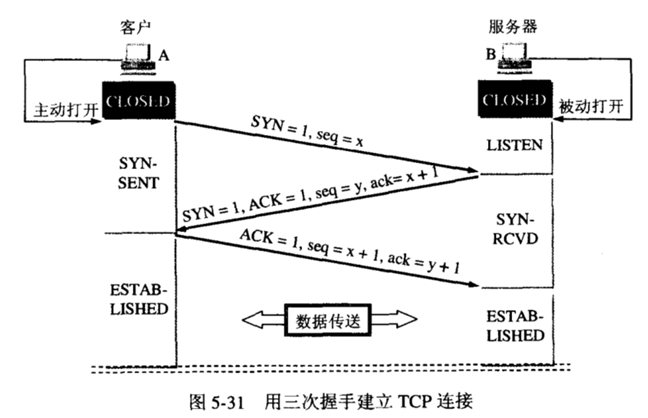
三次握手
- 客户端首先发起一个请求连接的报文,内容包含一个同步位SYN,和一个初始序号seq 此时客户端今日SYN-SENT的状态
- 服务端收到客户端的连接请求后,如果同意建立连接,就会返回一个同步位SYN,和一个ACK,并在初始序号seq上加1,之后服务端进入SYN-RECEIVED状态
- 客户端收到服务端的确认后,会告诉服务端确认信息已经收到,发送一个ACK,seq=第一次的seq+1,ack=y+1之后客户端进入established状态,服务端在收到客户端报文后进入established状态
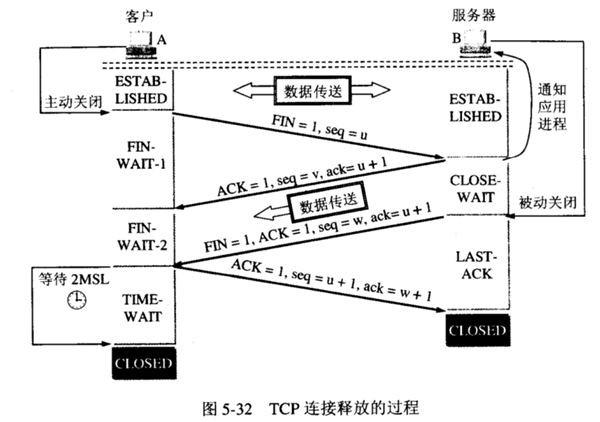
四次挥手
- 客户端先发起连接释放请求,然后不在发送报文.
- 服务端收到请求后给客户端一个应答告诉客户端报文已经收到,然后进入半关闭状态,此时后台可能还有数据包需要返回给客户端
- 服务端准备好后发送给客户端一个关闭连接的请求,表示服务端已经准备好了.
- 客户端收到服务端的请求后给一个回应,如果服务端收到回应后连接关闭,而客户端在发送请求后过一段时间才会关闭.
滑动窗口与粘包
TCP通过滑动窗口来进行拥塞控制,TCP会将每一个数据包编一个序号,然后要求接收方给一个确认并返回一个期望的下一个序号,例如发送方序号为2,接收方确认3,下次发送方就发序号为3的包,这个时候窗口就是1,也就是1个数据包,如果这个时候接收方确认的序号为5,那么发送端将会把3,4,5这3个数据包一起发送过来,这个时候滑动窗口为3表示一次发送3个数据包,TCP协议默认如果序号为5的数据包返回了确认,那么数据包3和4也算收到确认消息.
由于滑动窗口的作用,发送方和接受方就可以相互协调发送的速度,如果滑动窗口为0就表示目前处于网络阻塞状态,当网络窗口很大的时候,就会将多个数据包合并进行传输,而接收方看到的只是一个数据包,这就发生了粘包,而如果接收方把没有及时处理,数据包都在缓冲里,而下次一次处理多个数据包也会发生粘包,而TCP协议本身并没有提供拆包的机制,需要应用层具体实现,当然如果是收到一个数据包后直接写入文件,就不需要进行拆包处理,如果需要一个数据包一个数据包的解析就需要进行拆包,我们可以在每个数据包种加入包长度和分隔符进行区分.
我们在详细分析下粘包的产生的过程,当发送方发送两个数据包data1和data2,而接收方可能先收到data1在收到data2,也可能先收到data1的部分数据,然后在收到部分数据在收到data2,也可能一次收到data1和data2,收到的数据在缓冲区里,如果只接收了一半数据就读取就造成信息不完整,所以在进行拆包的时候需要对缓冲区进行定制.由于封包的时候包头会存放数据包的长度,所以接收到数据后线判断是否到达数据包长度,只有到了才开始拆包,
TLS
TLS在TCP的基础上实现了保密 双方加密传输,完整性校验 MAC校验,认证校验 双方都配备证书,防止身份被盗
http
TCP是传输层协议,而http是应用层协议,
https
linux网络模型
mmap 将一个文件或者其他对象映射到内存,数据可能被映射到多个pagecache上.由于应用程序无法直接操作设备,例如网卡,磁盘,内存条等,必须经过内核调用,mmap的好处是把设备的物理内存映射到虚拟内存,这样用户操作虚拟内存就相当于直接操作物理内存,相当于指针操作,不涉及系统调用,省去了用户空间和内核空间的转换.每一个用户进程都会配置一个虚拟的内存空间,例如3G的用户空间,1G的内核空间,每个进程的用户空间是独立的,但是内核空间是共享物理内存的.而java中的缓冲对象支持堆外内存DirectByteBuffer和mmap的MappedByteBuffer
linux最开始提供的时select/poll多路复用的模式模式,每一个socket都会对应一个文件,而select的过程会将监听的文件描述符发给内核,内核去线性扫描所有的文件描述符,并将有事件发生的socket交给用户处理.
而epoll将socket对应的文件在linux内核构建了一个红黑树,而用户需要监听某个socket或者取消某个socket的时候只是对这个红黑树进行增加和删除操作,而红黑树德增加和删除都是高效的,epoll采用事件驱动模式,当某个文件描述符的事件已经就绪后会自动唤醒,然后加入已经就绪的队列,然后返回给用户端,用户端直接通过mmap操作文件内容.所以epoll性能比传统的select/poll性能高很多,并且可以支持更多的连接.
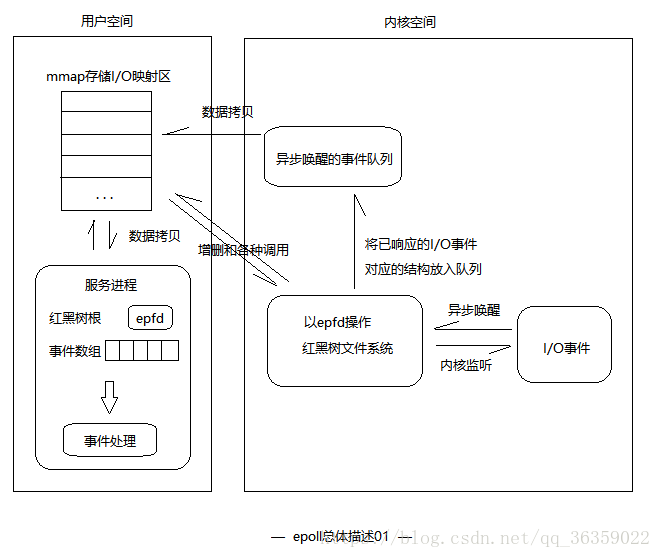
NIO
我们先回顾下传统http服务器的原理
- 1.创建一个serversocket并监听绑定一个端口
- 2.客户端来请求这个端口
- 3.服务端的accept获取一个socket
- 4.启动一个新线程处理这个socket
- 5.读字节流获取字节数组
- 6.解码获取http请求
- 7.处理http请求,返回一个httpresponse对象
- 8.编码httpresponse对象得到一个字节数组通过socket写入返回客户端
BIO: 在传统的文件IO和网络IO中,应用程序都需要调用底层操作系统提供的标准IO库read(),write()方法,这个过程需要从用户态也就是java进程切换到内核态,然后由操作系统的内核代码调用VFS的接口从磁盘或者网络将数据读取到内核的缓冲区,然后在由内核的缓冲区拷贝到用户进程,为什么要在内核设置一个缓冲区,因为比如我们读取文件的时候读取了第一行,大概率会读取第二行,而第二行大概率会在缓冲区就不用去磁盘读取了,而BIO就是在调用read的时候直接阻塞了,需要等从数据从内核缓冲区拷贝到用户缓冲区后才返回,(java中的bufferedInputStream其实是为了避免系统调用,因为系统调用需要从内核和用户空间转换也很慢),当应用程序调用read的时候,这个时候用户缓冲区可能还没有数据,所以会阻塞.
当服务端accept的时候是阻塞的,只有当有连接请求的时候才返回,read()的时候是阻塞的,只有客户端写入数据并且读取到堆内存才返回,write()是阻塞的,只有等到客户端收到数据才返回
NIO: 非阻塞的,由于采用多路复用模式,select/poll 当调用read的时候肯定是数据已经在用户缓存区了,可以直接获取不会阻塞,而为什么epoll会更高效?因为传统的select/poll会对多有监听的描述符进行线性扫描,所以会出现当有些数据已经准备好,但是由于select还没有结束,所以也会阻塞,而epoll事件驱动的模式,可以让IO完全异步不用等待.
jdk中的NIO有以下几个实现类
- ByteBuffer 数据缓冲区,,当调用read的时候数据会存在该buffer中,这个类也可以分配堆外内存进行处理
- ServerSocketChannel 服务端socket通道,全双工,读和写都是通过channel
- Selector 可以同时监听多个连接,select方法会阻塞到一直有新事件发生才返回
堆外内存
MappedByteBuffer 的原理是老的read是先将数据从文件系统读取到操作系统内核缓存,然后在将数据拷贝到用户态的内存供应用使用,而使用mmap可以将文件的数据或者某一段数据映射到虚拟内存,这个时候并没有进行数据读取,当用户访问虚拟内存的地址的时候会触发缺页异常,这个时候会从底层文件系统直接将数据读取到用户态内存,而MappedByteBuffer通过FileChannel的map方法进行映射的时候会返回一个虚拟地址,而MappedByteBuffer就是通过这个虚拟地址配合UnSafe获取字节数据,而操作系统在触发缺页异常的时候会去文件系统读取数据加载到内存,这个时候一般会进行预读取,一般为4KB,当系统下次访问数据的时候就不会发生缺页异常,因为数据已经在内存里了,为了让MappedByteBuffer读取文件的速度更高,我们可以对MappedByteBuffer所映射的文件进行预热,例如将每个pagecache写一个数据,这样在真正写数据的时候就不会发生缺页了。
netty
选择netty的理由
- netty的api更易用
- netty底层的IO模型可以切换,不影响开发
- netty自带粘包拆包功能
- netty自带各种协议的实现,包括websocket,http等
- netty规避了jdk nio中空轮询的bug
- netty的线程模型以及bytebuffer的定制使他处理IO更高效
- netty已经经历各大RPC框架,消息中间件的验证
- netty社区活跃
jdk nio 的bug 当selector.select()在某一key的时候会返回,并一直while循环,导出CPU100%导致其他任务什么也做不了,而netty的做法是检测到bug发生会重建一个selector,然后将之前老的Channel注册到新的selector上
我们通过下面的实例代码来分析netty的源码实现
public static void main(String[] args) throws Exception {
EventLoopGroup bossGroup = new NioEventLoopGroup(1);
EventLoopGroup workerGroup = new NioEventLoopGroup();
try {
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.handler(new SimpleServerHandler())
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) throws Exception {
}
});
ChannelFuture f = b.bind(8888).sync();
f.channel().closeFuture().sync();
} finally {
bossGroup.shutdownGracefully();
workerGroup.shutdownGracefully();
}
}
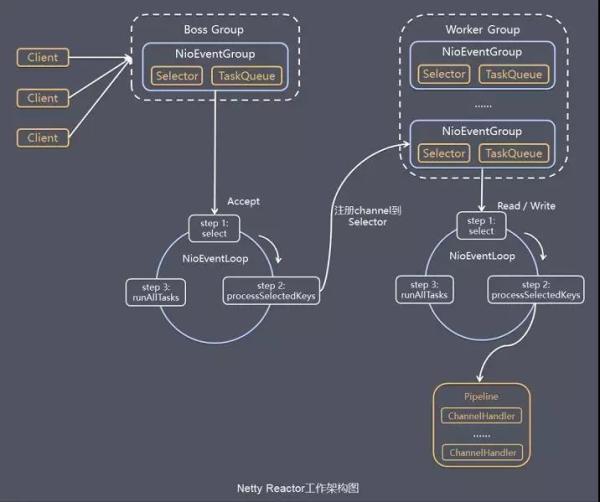
reactor模型也就事件驱动模型,类似于dispatcher,当main reactor线程监听到客户端连接后将这个连接交给sub reactor线程,sub reactor线程监听到读写请求后,派发给工作线程进行处理
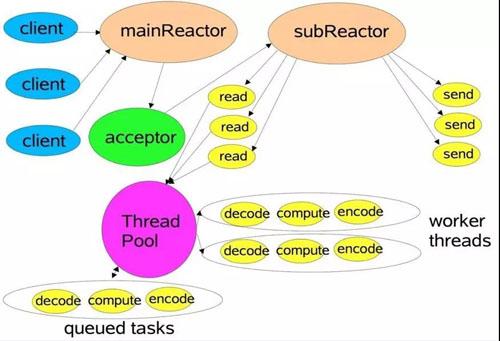
-
ServerBootstrap 启动的辅助类,通过设置一系列参数,最后开始监听端口,参数包括:IO模式,是NIO还是BIO,两个线程池,一个处理IO连接请求,一个处理IO读写请求,另外还要设置服务端启动过程中的处理逻辑和当连接建立时候的处理逻辑
-
EventLoopGroup 其实就是一个线程池,一直while true轮询,看是否有新的IO事件,处理IO事件,以及其他自定义任务
-
channel NIO双向通道,通过channel进行read和write,提供当前网络连接的参数,状态,
-
bytebuffer 利用堆外内存实现零拷贝
-
channelhandler 在接收到一个连接后的后置处理,数据流读取,解码,处理,返回数据等操作,该handler会返回所在pileline的下一个处理器
-
channelPileline 保存channelhandler的list,用于处理或者拦截channel的入站和出站事件
-
ChannelFuture netty中的操作都是异步的,可以通过isDone来判断是否操作完成,通过isSuccess判断操作是否下发成功,通过addListener来注册监听器
netty提供了固定长度的拆包器,分隔符,按行等
如何实现心跳检测
我们首先想到的时TCP的keepalive机制,但是如果太过底层,如果我们要实现检测到连接断开后进行重连到其他节点,就只能在应用层实现,简单的想法是,以一定时间间隔发生一个检测包PING,服务端收到心跳检测后返回一个PONG,客户端将返回的时间记录到本地,每次收到PONG就更新本地记录,然后有一个本地定时任务检测这个当前时间和本地记录缓存的时间是否超过阈值,如果超过阈值就执行重连就可以了.
这样的实现没什么大问题,只是当客户端和服务端在正常通行的时候,其实不需要发送心跳包得,因为他们如果能够正常通信就代表连接是正常的,所以最好是在客户端长时间和服务端没有正常通信的时候发送心跳包,想想有点麻烦,好在netty已经帮我们实现了,IdleStateHandler,这样就可以当客户端在一定时间内没有收到写消息的时候就发送心跳包,但是IdleStateHandler在检测到网络断开后会调用destroy方法,把之前的定时任务删掉,所以需要额外的定时任务进行重试.