前言
在早开始接触消息队列是ActiveMQ,由于ActiveMQ是支持JMS规范的,但是由于微服务的兴起,传统的消息队列和JMS规范已经无法满足应用分布式部署的需求,所以后续出来一些消息中间件已经不在严格遵守JMS规范,例如我们今天会分析的rocketMQ.
JMS规范是一套类似于jdbc的接口,他提供了发送和接收消息相关的API,各个消息中间件都会实现该api,这样在使用不同厂商的消息中间件的时候可以使用同一套接口.JMS规范定义了,消息的发送者,接收者,点对点,发布与订阅,消息队列queue,消息主题topic.拉取消息的模式.
rocketMQ
rocketMQ是阿里巴巴开源的一套分布式消息中间件,提供了消费者和生产者都可以弹性扩展的能力,并且多消息的消费速度可以自动进行流控,避免消息拉取太快,而消息处理速度跟不上,同时提供了亿级的消息堆积能力,同时提供了顺序消息,事物消息,消息过滤,消息失败重试等,同时消息持久化到磁盘避免消息丢失,支持消息回溯,使消费者可以重新到指定的时间重新进行消费,当然选择rocketmq主要还有以下原因,活跃的社区和经历过双十一的考验.
组件介绍
- NameServer 名字服务,类似于ZK的注册功能,nameServer接受broker的注册和注销请求以及topic和broker的管理信息,consumer和producer通过nameserver获取某个topic下的所有的queue,以及queue分配在哪个broker上的
- topic 消息的主题,一般某一个具体的业务会在broker上创建一个消息topic,一个topic可以有不同的消费组,每个consermer group之间的消费互不影响
- queue 消息队列,逻辑上可以指具体存储消息的地方,(实际上消息存储在磁盘上),而一个topic可以创建多个queue,每个queue可以被不同consumer group同时进行消费.
- Consumer 消息的消费端,可以支持集群部署,订阅某一个topic后,可以从这个topic对应的queue上拉取消息,目前虽然支持pull和push,但是建议使用pull开控制消费速度
- Provider 消息的生产者,可以支持集群部署,当和一个topic关联后,可以将消息推送到broker上进行存储
- Provider Group 一类producer的集合,这些producer往往在一个集群内,发送同一个消息,当发送事物消息的时候,如果消息队列需要去producer进行反查,如果某一个producer挂了可以去这个group下的其他producer查询
- Consumer Group 一类consumer的集合,避免在consumer集群下,每个consumer都会订阅某个topic后收到消息后重复处理,同一个group下的所有consumer只有一个会收到消息并处理
- Broker 消息服务器,支持集群部署,负责存储消息,维护消息发送的状态,并将topic信息发送给nameserver
部署模型
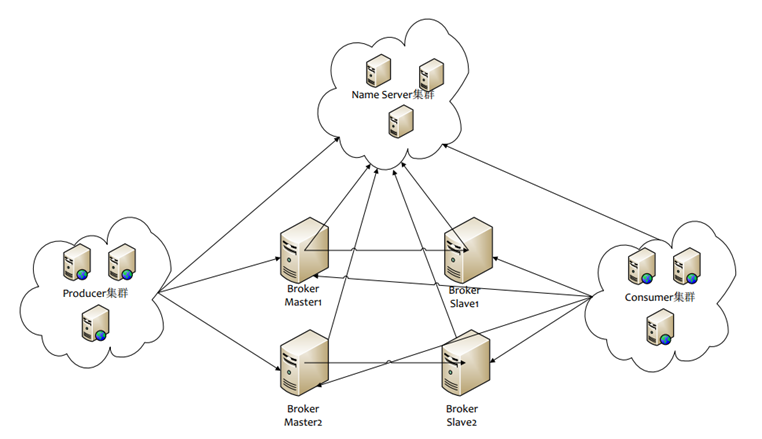
- 单Master模式 单点风险
- 多Master模式 靠RAID保证消息不丢,会丢失部分消息
- 多Master多Slave master宕机后,对应的slave跟上去,但是如果master和slave之间的复制有同步和异步,同步会降低吞吐量,异步可能会有少量消息丢失.
拉取模式
RocketMQ采用推拉结合的模式,客户端以一定频率向broker拉取指定队列上是否有消息,如果有消息就批量拉取,如果没有消息就等待,直到超时或者有消息在返回,而服务端收到生产者的消息后也会主动推送给客户端一个通知,客户端收到通知后会主动过来拉取消息,这种模式可以在最大程度上保证消费者可以按自己的处理速度去消费.
消息过滤
消息过滤可以实现,MessageFilter接口,读取消息属性进行过滤,也可以直接通过tag来实现
顺序消息
要严格保证消息的顺序,那么只能有一个队列了,当然如果使用主从,也可以保证大部分的顺序
消息回溯
消费者如果要回溯到1个小时以前的节点重新进行消费,可以在broker上重置queue的offset,因为每一个consumergroup在broker上都维护了对应的队列的消费位置,每次都从指定位置拉取消息,如果要重塑只需要根据时间reset这个offset的值
存储设计
rocketMQ的存储信息主要有以下4类
- config 主要存取控制和状态信息,比如某个consumer group消费到某个queue的offset
- commitlog 实际的消息存储,每个文件1G
- index 索引文件,如果消息体包含index信息,相当于mysql里的二级索引,方便根据某个key去commitlog查询消息
- consumeQueue 每个文件6M,这个文件对应消费端实际消费的逻辑队列信息,通过该队列去commitlog检索,队列里存储的是该消息存储在commitlog里面的偏移量,以及tag值
存储流程
- broker收到producer发送的消息后先进行存储到cimmitlog,这个时候消息一般在内存,一般会配置异步刷屏,所以会在合适时机才会将消息从内存存储到磁盘
- 从接收消息到生成commitlog后会根据消息里面是否有配置index,如果有的话会更新索引文件
- 同时在生成commitlog后会将该消息分发到对应的consumerqueue上(生成commitlog在内存就算完成,不一定要刷到磁盘)
rocketMQ利用堆外内存来实现消息的告诉存取,当broker收到producer的消息后,会存储到堆外内存,消费端去拉取消息的时候,会首先到consumerqueue,然后在去检索消息,如果在内存有就直接从内存取,如果内存没有会从磁盘读取到内存在返回,rocketMQ将内存分成一个个pagecache,每个缓存页为4kb,同一个queue的消息存储在同一个pagecache内,当去拉取消息的时候可以大概率的在一个pagecache内,这样即使在内存也可以做到批量读取消息的时候是一块连续内存.
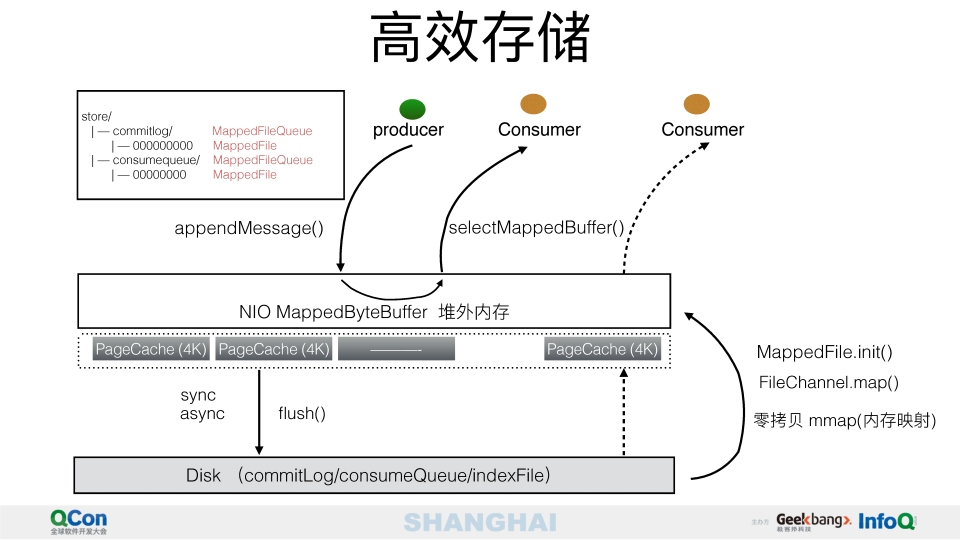
为什么读和写都是顺序读写性能高于随机读写,因为OS在读取文件的时候都是以一个pagecache为单位进行读写的,先将数据load到内存,内存中写完在write到磁盘,所以下次顺序读写的时候基本上大概率会在内存,所以顺序读写的速度可以接近内存.
由于rocketmq支持多个producer同时写消息,那么很有可能多个producer收到消息后会往同一个commitlog写数据,避免数据错乱,所以写数据的时候会加锁.当然这里的设计可能会加自旋锁.由于rocketMQ可以支持一个topic多个队列,多个消费者可以并发的进行消息读取,虽然由于写锁保证了commitlog是顺序append操作,然后consumerqueue也是append操作,都是顺序写,但是consumerqueue存储的是commilog的偏移量和tag,所以还是需要借助offset去commitlog上读取,由于消息分布在不同的queue上,所以单个queue上的消息和commitlog上的顺序不一致,所以实际是consumer去拉取消息的时候并不是顺序读的,而是随机读,但是整体上依然是通过commitlog从旧到新的顺序,所以还是可以借助pagecache.
在存储设计上kafka是只维护了一个commitlog,这样可以保证consumer和producer都是严格的顺序读取,理论上来说性能会更高,rocketMQ将多个consumerQueue对应同一个commitlog,导致同一个queue上无法顺序读,但是多个consumer之间可以在queue之间并行消费,也提高了吞吐量,但是kafka存储上当一个commitlog太大的时候,kafka里面称为partition,就会拆分为多个partition,而消费者无法并行的进行消费,那么在多个文件之间顺序读写可能性能并不会很高了.
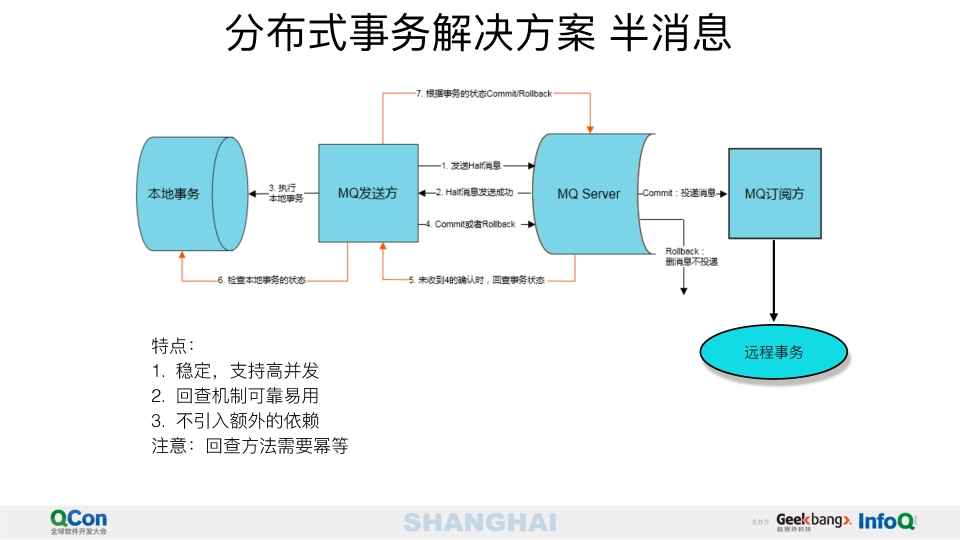
事物消息
rocketMQ通过一个叫半消息(Half Message)的服务来实现事物消息,使用方需要将本地事物和消息发送放在一个事物内,当本地事物提交或者回滚的时候通知消息服务器提交和回滚,如果本地服务发给消息服务器的提交或者回滚请求没有响应,消息服务器可以定时查询所有没有提交的消息,去服务提供方查询消息的状态,看是提交还是回滚.
事物消息的存储设计: producer发送事物消息,broker接收后会将半消息存储在一个half topic里,这个里面存储的消息都是没有commit的,并且无法被消费者消费的,如果producer发送commit或者rollback信息给broker,broker会将信息存储在op topic里,如果是rollback会从half topic里移除消息,如果是commit 会从half topic移动到用户设置的topic下,之后该消息就可以被消费者看到,同时后台有个线程去查看half topic里面长期没有commit的消息,去反查producer查询本地事物的状态,如果本地事物是提交或者回滚会进行对应的操作,反查通过缓存producer对应的channel进行,如果此时producer已经挂了,就会从其他group内其他producer发起查询请求.
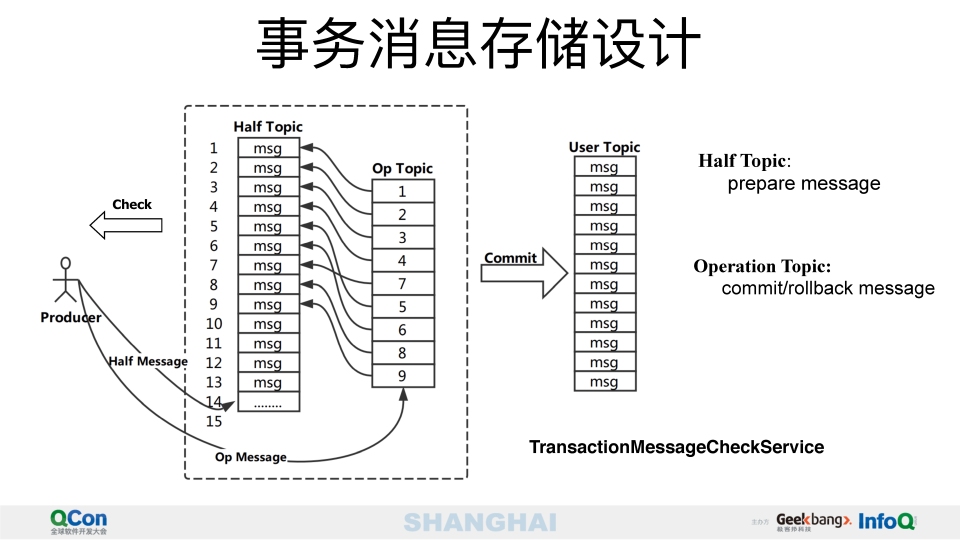
下面是producer如何发送事物消息和提供回查接口

消息发送和负载均衡
- 1.先获取topic对应的路由信息(路由信息会从namesrv返回,在客户端缓存,返回这个topic对应哪几个broker以及每个broker上有多少个队列)
- 2.如果没有获取到,可能没有topic,需要自动创建,自动创建是客户端发信息到namesrv,namesrv再去请求broker,broker创建好后返回
- 3.根据路由策略获取一个queue(从所有的queue中根据对应的路由策略获取queue,一般为轮询,然后在判断这个queue对应的broker是否健康,健康就返回) 这个地方就可以做到broker的高可用
- 4.所以 我们发现消息是发给哪个broker的哪个queue是在客户端发送的时候决定的,不是在生成commitlog之后在派发的,这样我们就可以指定都发送到某一个固定queue了,也就是queue的负载均衡是在producer做的
- 5.消息发送的时候会构建发送请求,里面包含了消息体和队列信息,topic信息等,消息体里面会增加一个消息ID,
- 6.如果消息重试多次后还是失败就会进入死信队列,一个固定的topic
消息消费
一个队列只能被一个客户端消费,当有多个队列,只有一个客户端的时候,这个客户端需要去4个队列上消费,当只有一个队列的时候只会有一个客户端可以收到消息,所以一般情况下需要客户端数量和队列数量一致,客户端一般会保存每个队列消费的位置,因为这个队列只会有一个客户端消费,所以这个客户端每次消费都会记录下队列的offset,broker端也会记录同一个grouo消费的offset
云原生
计算和存储分离,支持openmessaging