FESCAR (Fast easy commit and rollback),是阿里GTS的社区开源版本,基于现有的分布式事物解决方案,要么像XA这种会有严重的性能问题,要么像业务补偿,TCC,SAGA,可靠消息保证等,这种需要根据业务场景在应用中进行定制,我们不希望引入微服务后给业务层带来额外的研发负担,另外一方面不希望引入分布式事物后拖慢业务,所以FesCar的初衷就是对业务0侵入,并且高性能.
下面先通过官方上的介绍,看下fescar的思想,后面在结合代码看下fescar的具体实现细节
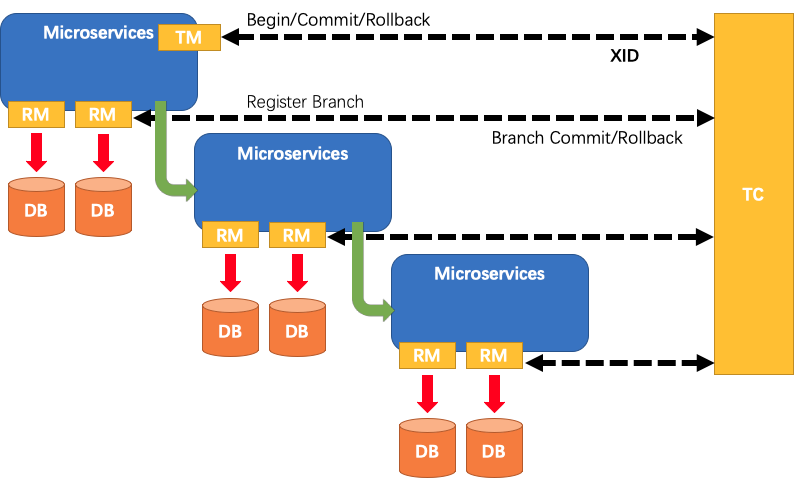
我们先简单回顾下XA里面分布式事物的三个角色,TM事物管理器.负责发起一个全局事物,TC事物协调器,独立在应用层外,负责维护全局事物和分支事物的状态,来决策提交还是回滚,RM:资源管理器,存储实际状态的容器,像硬盘,数据库,消息中间件,内存等都可以称为RM,Fescar将RM作为一个二方包的形式迁入到了应用层,作为应用层和TC进行通讯的代理,并且协助本地事物处理.
- 1.TM向TC申请开启一个全局事物,全局事物创建成功,并返回一个唯一的XID
- 2.XID在微服务调用链路中进行传递,dubbo可以通过filter方式,spring cloud也很方便,RPC服务端收到XID后存放在本地线程局部变量threadlocal中
- 3.分支事物RM向TC注册分支事物,将其纳入XID对应的全局事物管理中
- 4.TM向TC发起针对XID的全局事物的提交或者回滚操作
- 5.TC调用XID管辖下的分支事物完成提交和回滚
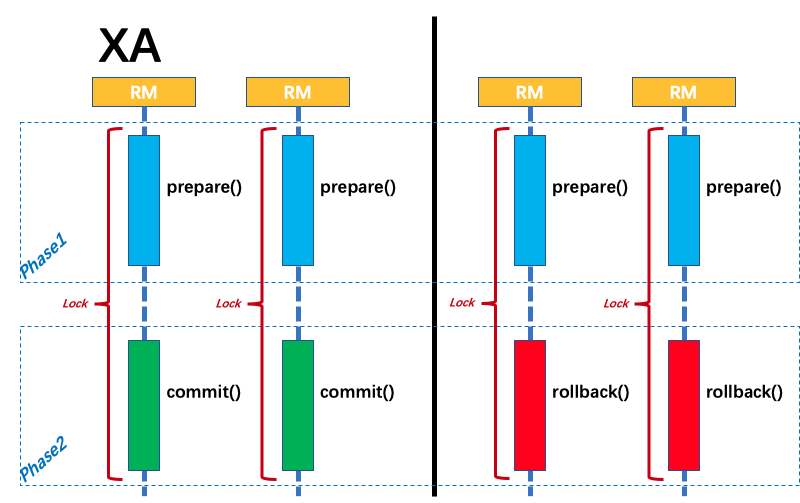
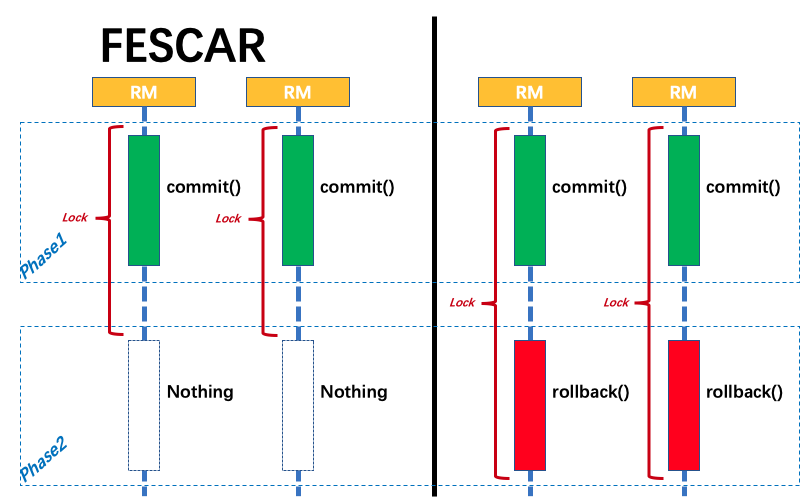
FESCAR取消了数据库层的prepare操作,而是直接进行commit操作,这样就不会带来昂贵的数据库锁开销,而每一个commit操作对应的都是数据库的本地事物,这个改变是Fescar性能高的主要原因,同时使他牺牲了隔离性,导致目前Fescar只能支持读未提交的隔离级别,如果要实现读已提交需要应用层做一些定制.
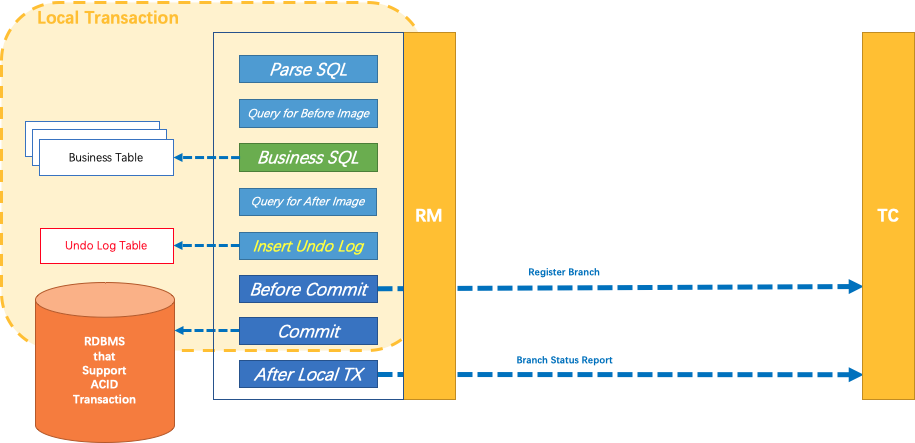
Fescar的RM插件,重新实现了一遍JDBC,从而拦截掉数据库的sql进行解析,并生成undolog,以及事物提交后的增强处理,这种设计使应用方完全无感,只需要开启一个全局事物

undolog是存储在业务方本地的数据库实例里,这样业务更新和插入undolog在一个本地事物内,可以保证事物回滚的时候一定有undolog.
目前fescar刚开源,在可靠性上还需要验证,目前社区也在计划完善一些新功能.
下面我们分析下Fescar的一些核心功能
事物管理器
我们先看下全局事物的三个核心接口,begin,commit,rollback,我在代码中都加了注释
public interface GlobalTransaction {
/**
* Begin a new global transaction with default timeout and name.
*
* 开启一个全局事物,像TC发起请求,返回一个XID,并将这个XID进行缓存到ThreadLocal
*
* @throws TransactionException Any exception that fails this will be wrapped with TransactionException and thrown
* out.
*/
void begin() throws TransactionException;
/**
* Commit the global transaction.
*
* 提交一个全局事物,将XID发给TC,并清除threadlocal里的缓存
*
* @throws TransactionException Any exception that fails this will be wrapped with TransactionException and thrown
* out.
*/
void commit() throws TransactionException;
/**
* Rollback the global transaction.
*
* 回滚一个全局事物,将XID发给TC,并清除threadlocal里的缓存
*
* @throws TransactionException Any exception that fails this will be wrapped with TransactionException and thrown
* out.
*/
void rollback() throws TransactionException;
}
然后我们在看下事物处理模板,也就是我们使用的入口,也是接入fescar唯一要关心的一个地方
public class TransactionalTemplate {
/**
* Execute object.
*
* @param business the business 只需要传人一个TransactionalExecutor就可以了,业务实现放在execute里面就可以了
* @return the object
* @throws ExecutionException the execution exception
*/
public Object execute(TransactionalExecutor business) throws TransactionalExecutor.ExecutionException {
// 1. get or create a transaction
GlobalTransaction tx = GlobalTransactionContext.getCurrentOrCreate();
// 2. begin transaction
try {
tx.begin(business.timeout(), business.name());
} catch (TransactionException txe) {
throw new TransactionalExecutor.ExecutionException(tx, txe,
TransactionalExecutor.Code.BeginFailure);
}
Object rs = null;
try {
// Do Your Business
rs = business.execute();
} catch (Throwable ex) {
// 3. any business exception, rollback.
try {
tx.rollback();
// 3.1 Successfully rolled back
throw new TransactionalExecutor.ExecutionException(tx, TransactionalExecutor.Code.RollbackDone, ex);
} catch (TransactionException txe) {
// 3.2 Failed to rollback
throw new TransactionalExecutor.ExecutionException(tx, txe,
TransactionalExecutor.Code.RollbackFailure, ex);
}
}
// 4. everything is fine, commit.
try {
tx.commit();
} catch (TransactionException txe) {
// 4.1 Failed to commit
throw new TransactionalExecutor.ExecutionException(tx, txe,
TransactionalExecutor.Code.CommitFailure);
}
return rs;
}
}
有没有发现跟我们平时使用的JTA用法一样,由于分支事物是RPC调用,所以存在网络超时的情况,所以分支事物如果超时了,即使分支事物的本地执行成功了,全局事物一样会进行回滚,因为这里会捕获这个超时异常,后面我们在分析为什么要这样设计.
xid怎么在rpc中传递
我们在做分布式链路监控的时候,也需要在rpc之间传递一个traceid,方法类似,如果是dubbo,我们可以写一个filter
@Activate(group = { Constants.PROVIDER, Constants.CONSUMER }, order = 100)
public class TransactionPropagationFilter implements Filter {
private static final Logger LOGGER = LoggerFactory.getLogger(TransactionPropagationFilter.class);
@Override
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
String xid = RootContext.getXID();
String rpcXid = RpcContext.getContext().getAttachment(RootContext.KEY_XID);
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("xid in RootContext[" + xid + "] xid in RpcContext[" + rpcXid + "]");
}
boolean bind = false;
if (xid != null) {
RpcContext.getContext().setAttachment(RootContext.KEY_XID, xid);
} else {
if (rpcXid != null) {
RootContext.bind(rpcXid);
bind = true;
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("bind[" + rpcXid + "] to RootContext");
}
}
}
try {
return invoker.invoke(invocation);
} finally {
if (bind) {
String unbindXid = RootContext.unbind();
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("unbind[" + unbindXid + "] from RootContext");
}
if (!rpcXid.equalsIgnoreCase(unbindXid)) {
LOGGER.warn("xid in change during RPC from " + rpcXid + " to " + unbindXid);
if (unbindXid != null) {
RootContext.bind(unbindXid);
LOGGER.warn("bind [" + unbindXid + "] back to RootContext");
}
}
}
}
}
}
RootContext是fescar的threadlocal容器,RpcContext是dubbo得threadcontext容器,Attachment可以让dubbo在远程调用过程中携带更多地参数,服务调用方传递xid,服务提供方接收xid并保存,服务调用结束记得清空threadlocal以防止内存泄露.
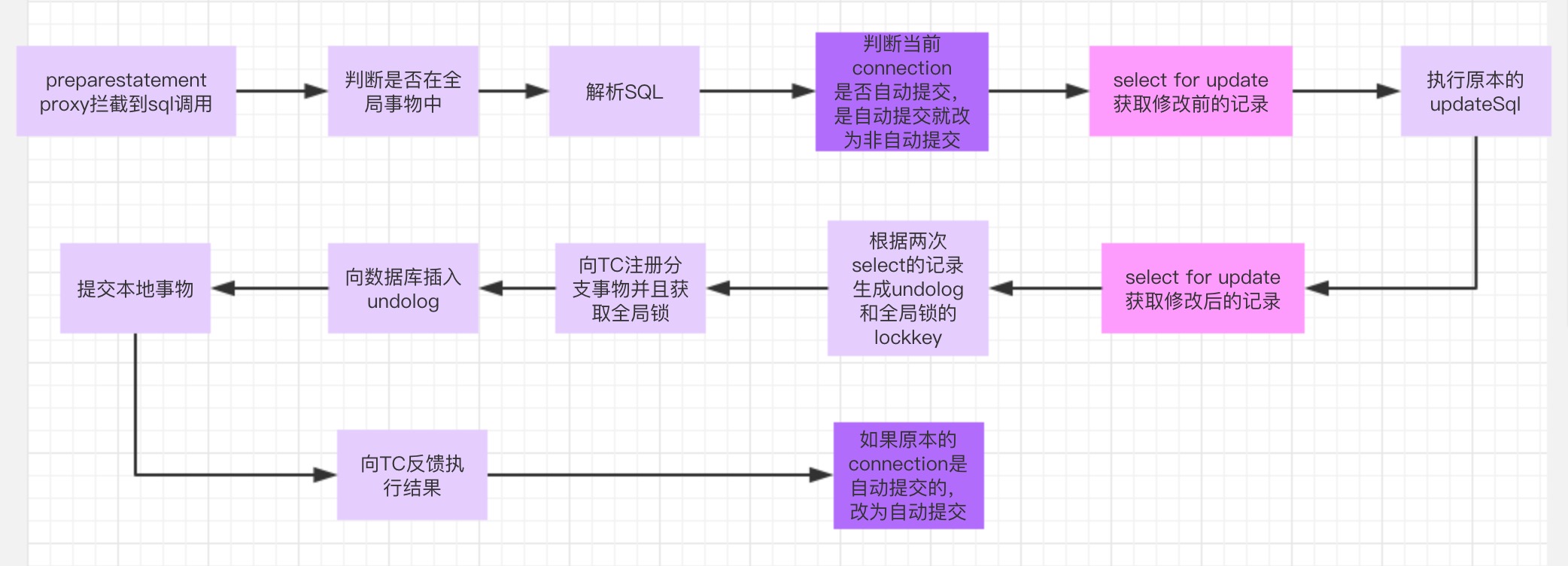
分支在一阶段的处理流程
PreparedStatementProxy -> ExecuteTemplate -> UpdateExecutor ->ConnectionProxy
- 0.sql进入jdbc的PreparedStatement中,然后这个jdbc对象被PreparedStatementProxy代理,进入他的execute方法
- 1.查看自己是否在一个Fescar的全局事物中,根据线程本地变量threadlocal中是否存在全局事物id进行判断,具体代码在ExecuteTemplate中
- 2.如果存在,就进入jdbc代理中,解析sql,根据类型选择不同的执行器

- 3.使用 select for update 查询获取原始当前update的记录当前值,就是修改前的值
- 4.执行原本的update修改记录的值
- 5.使用 select for update 查询获取update后的值,就是修改后的值
- 6.根据修改前和修改后的值,生成undolog,并根据主键的值生成lockkey放入context中
- 5.向TC请求,注册分支事物并将lockkey传给TC加上全局锁
- 6.如果注册并且获取锁成功,将把undolog插入数据库中
- 7.提交本地事物,并向TC反馈执行结果 (本地事物中包含原本的执行语句和插入undolog)

我们发现分支事物上的RM操作是基于statement和connection,在原来的connection上做了增强,用的时同一个物理connection,所以分支应用上的分支的定义为一个本地事物,所以 在一个RPC实现中,一个方法中如果存在多个sql语句,那么将会注册多个分支,向TC注册多次,如果这个方法在一个本地事物中,那么即使多个sql最终一起提交,并且只会向TC注册一次,undolog也是一起插入数据库的,这个地方注意下,如果这个connection是自动提交的,为了让update语句和插入undolog放在一个本地事物中,所以会将connection改为非自动提交,开启一个事物,在用完只会在改为自动提交,不要影响应用程序.

我们回顾下分支一阶段的处理流程
二阶段的处理流程
-
1.如果所有的分支都返回执行成功,TC将立即释放全局锁,并且TC异步通知分支删除undolog
-
2.如果有一个分支事物返回执行失败,则TC发起请求执行undolog,所有undolog执行成功了,释放锁,异步删除undolog
如何实现读已提交
目前官方给出的方案,在需要进行读取全局事物已经提交的记录的话,需要将select 语句后面加上for update,fescar发现加上排他锁后,会去TC获取对应的锁,如果没有锁上就执行,锁上就自旋等待,为了避免读取未提交的记录,后面全局事物回滚了,就导致脏读,当然目前可能大部分应用都可以接受这种情况,例如在扣商品份额的时候都会最终在校验一次, 当然我们也可以借助undolog实现一个read-view,让这条sql语句读取到这个全局事物还没有执行之前的数据.
目前fescar的实现方式是在sql解析后如果发现是select for update语句,将会进入SelectForUpdateExecutor执行器,不管是不是在一个全局事物中,都需要去TC看下是否被锁住,这里将不会获取锁,只是校验锁是否会释放.
如果分支超时,实际已经执行成功,那么肯定是已经向TC注册成功的,那么如果TM发起回滚,分支可以正常回滚,没有毛病,如果超时后,分支本地事物还没有提交,那么回滚请求已经到达分支,那么将会回滚失败,但是TC会重试不停进行回滚.
实现HA的挑战
TC目前是一个单点,如果需要集群部署,则需要一个服务发现的系统,让TC可以自动扩展,应用不需要关心TC具体节点,而TC的全局锁就不能直接放内存了,可能需要借助第三方存储系统,mysql或者etcd
实现XA的方案
可能需要在分支事物中,当解析到在一个全局事物中,不会进行commit,等到所有分支都返回成功了,事物管理器发起commit请求给TC,然后TC在通知各个分支进行提交,和rollback流程差不多