JAVA对象内存布局
首先我们明确下java中的基本数据类型
- byte 占1字节 由于1字节占8位(bit),所以最大可以表示 正负2的7次方
- short 占2字节 16bit 最大表示 正负2的15次方
- int 占4字节 32bit 最大表示 正负2的31次方
- char 占2字节 16bit 范围 \u0000 到 \uffff
- boolean 占1个字节 8bit 只有01 前面7为补0
- float 占4个字节 32bit
- double 占8个字节 64bit
- long 占8个字节 64bit 最大表示 正负2的63次方
- reference 在32位机器上占4个字节 也就是32位 ,在64位机器上占8个字节,也就是64位,在开启指针压缩后占4个字节
由于操作系统有32位和64位之分,就是每次读取数据的最小单位是32bit还是64bit,由于double和long是64bit,所以在32位机器上要分两次读所以不是原子操作,可能出现数据错乱,如果加上volatile不会错,在64位机器上不会有错乱
在64位机器上,一个java对象的对象头占16字节,前面8个字节存储标记信息,主要包含对象锁信息,哈希码,GC信息,后面8个字节是一个指向类对象的指针,当开启指针压缩后只需要4个字节,也就是对象头在开启指针压缩后占用12个字节.
java虚拟机会对内存进行对齐,一方面是方便指针压缩后进行内存寻址,java虚拟机要求long,double,以及引用类型的地址是8的倍数,另外对象头加上实例数据加上padding是8的倍数,另外一方面,让一个字段只出现在一个CPU的缓存行里,如果字段不是对齐的就会出现一个字段在两个缓存行,那么一个字段的读写都要同时操作两个缓存行,影响程序执行效率,另外对象里的字段会进行重排序用来节省空间.
jdk中可以通过,获取UnSafe类来获取到一个属性在一个对象里面的内存相对对象起始位置的偏移量,有了这个偏移量,就可以通过Unsafe来操作这个属性在对象里的值,包括读取和写入,jdk里的反射,atomic类,LockSupport阻塞thread都是用的这个方法.
一个java对象本身占有的内存大小,为对象头的大小加上对象里面各个属性的大小,属性分为基本类型和引用类型,属性还需要包含从父类继承下来的属性,属性在内存中的布局需要啥8的倍数,所以会有padding补全,如果要计算一个对象占有的总空间的大小,需要进行递归遍历加上引用对象所占的空间
数组对象的对象头占有24字节 因为要额外存储使用的内存信息,而对象内存的分配也不一定会在堆空间,可能会放在栈空间,如果jvm开启了逃逸分析,发现这个对象只会在某一个方法内使用,不会逃逸到方法外部那么这个对象可以不用在堆上分配,当然java IO也提供了直接使用堆外内存的方式.
关于float和double的精度问题,我们也分析下
float a = 3.14159f;
存储为 0.314159 乘以 10 的1次方 所以浮点类需要存储 符号位,数字,指数
- float :1位符号位,8位指数位,23位尾数位 所以2的23次方 最多只能存储7位数字
- double :1位符号位,11位指数位,52位尾数
损失精度和浮点数的位运算有关,而bigdecimal就不会有这个问题.
JAVA 内存结构
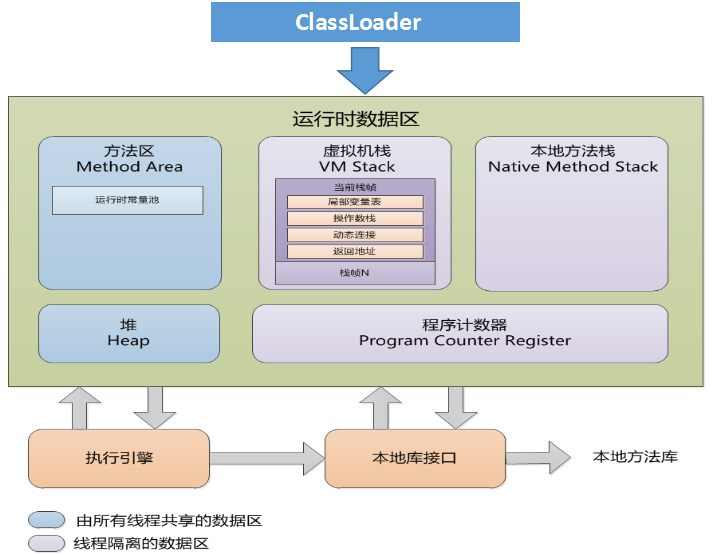
- 程序计数器 是JVM中一块较小的内存,保存着当前线程执行的虚拟机字节码指令的内存地址,这个是线程私有的,用来在线程切换的时候可以找到之前执行的位置
- 堆 存储java实例的地方,也是java线程new 一个object的时候分配对象的地方,分为年轻代和老年代.
- 虚拟机栈 是跟线程绑定的,每创建一个线程就会创建对应的线程栈,栈中会有多个栈帧,每调用一个方法就会压入一个栈帧,方法的执行参数和结果会放在栈帧中,一个方法执行结束后,栈帧会立马被回收.
- 本地方法栈 执行native方法时候创建的线程栈空间
- 方法区 用于存储类信息,以及常量池和静态变量,以及即使编译器编译后的的指令,即使编译器会将经常被执行的字节码编译为机器码用于提高执行速度.
缓存一致性
- 缓存一致性协议 由于CPU和主内存的处理速度存在差异,为了屏蔽这层差异每个CPU上都存有多级缓存,L1,L2,L3,现代计算机大多有多个CPU,那么怎么保证这些缓存上的数据的一致性呢,早期CPU通过在主线上加LOCK来实现,这种全局锁性能低下,会阻塞其他数据的读写,后来一些大厂就发布了缓存一致性的标准,其中比较出名的就是Intel的MESI.
MESI的核心思想是,当CPU写数据的时候,如果发现操作的变量被其他缓存共享,就会发一个信号通知其他CPU的缓存失效掉这个变量,当其他CPU需要使用这个变量的时候发现已经失效,就会重新去主内存获取.MESI规定每个缓存行有4个状态.
- M:这个缓存行的数据已经被CPU改过了,和主内存不一致
- E:这个缓存行,只有这一个副本,并且和主内存一致
- S:这个缓存行,存在多个副本,并且当前和主内存一致
- I:这个缓存行已经无效了
缓存行伪共享:由于CPU的缓存的最小单元是缓存行,目前大部分CPU的缓存行大小为64字节,这样就导致多个变量可能存在一个缓存行里,而这两个变量可能被多个cpu共享,假设变量x和y在同一个缓存行,CPU1修改了变量X的值,那么就会给CPU2的缓存行发一个信号失效了他上面的缓存行,那么CPU2如果去读取Y的值的话发现缓存行已经无效,就会去主内存去读,影响了效率,有时候程序为了提高效率会主动进行填充,让这个歌对象占有64个字节,这样就不会分配到多个缓存行,disruptor就是采用的这种方式,不过这种方式目前只适用于jdk6,因为jdk7编译器的逃逸分析会主动去掉没有用到的字段,所以只能变量的增加一个父类来避免被优化,好在jdk8增加了一个@Contended注解主动做缓存行填充.
以下为jdk6的做法
public final static class VolatileLong
{
public volatile long value = 0L;
public long p1, p2, p3, p4, p5, p6; // comment out
}
以下为jdk7的做法
public class VolatileLongPadding {
public volatile long p1, p2, p3, p4, p5, p6; // 注释
}
public class VolatileLong extends VolatileLongPadding {
public volatile long value = 0L;
}
以下为jdk8的做法,jvm启动的时候需要加上-XX:-RestrictContended才生效
@Contended
public class VolatileLong {
public volatile long value = 0L;
}
关于逃逸分析,两个例子,当jvm检测到一个对象的引用不会到这个方法以外,那么这个对象可以在栈里分配内存,这样这个方法执行结束就随着栈帧被回收,如果检测到某个变量根本没有用就会在编译字节码的时候去掉
JMM 内存模型
为了保证共享内存的正确性(可见性,有序性,原子性),内存模型定义了共享内存系统中多线程程序读写的操作规范.目前JMM采用的方案是限制编译器优化和插入内存屏障.JMM规定所有的共享变量都存储在主内存,而每条线程有自己的工作内存,工作内存中存储的是主内存中的拷贝,工作内存不能直接修改主内存的变量. 必须先从主内存load到工作内存在save到主内存,线程间的变量传递必须经过主内存,JMM规定了如何在工作内存和主内存之间做数据同步.
- lock 作用于主内存变量,将一个对象标记为某个线程独占状态
- unlock 作用于主内存变量,将一个处于锁定状态的变量释放,释放后其他线程可以将其锁定
- read 作用于主内存变量,把一个变量的值从主内存读取出来,并传输到工作内存
- load 作用于工作内存,将read的值赋值给工作内存的变量
- use 作用于工作内存的变量,将工作变量的值传递给执行引擎进行计算
- assign 作用于工作内存的变量,将执行引擎计算的值赋值给工作内存中的变量
- store 作用于工作内存的变量,将其值传递到主内存中
- write 作用于主内存的变量,将store阶段的值赋值给主内存的变量
如果要将一个变量从主内存复制到工作内存,将会按顺序执行read和load,但是read和load之间可能会有其他变量的操作,以上8个操作都是原子的,有些必须成对出现并且有顺序保证,在多个线程之间的要保证线程安全,需要借助lock和synchronized,volatile来插入内存屏障保证hapen-before的顺序.
GC
我们先看下传统的几种GC算法
- 清理法 这种方式会直接清理掉非存活的对象,会造成内存碎片,导致可能的内存不足以及内存分配比较困难
- 整理 这种算法将非存活对象清除后,将存活对象整理到一起,这样避免了内存碎片,但是由于要进行大量的内存拷贝性能低下
- 复制 这种算法把存活对象移动到另外一块内存中,然后把当前内存块全部清理掉,这种方式导致内存使用率只有一半
- 分代 这种算法将内存划分为4块,一块eden区,两块survivor区,和老年代,每个线程通过TLAB一次在eden区申请一大块连续内存,线程内new一个对象的时候都在这个内存块分配,不够的时候在通过tlab申请,如果eden区不够了就会触发一次young GC, GC的时候会扫描eden区和其中一个from块的survior区,将存活对象拷贝到survivor的to块中,然后切换form和to的位置,多次yonng GC后会记录每个对象在from和to切换的次数,如果超过一定次数就会移动到老年代.这种算法的理想情况下是eden上的绝大多数对象都是超生夕死的,活着的对象很少,所以需要复制的对象很少.
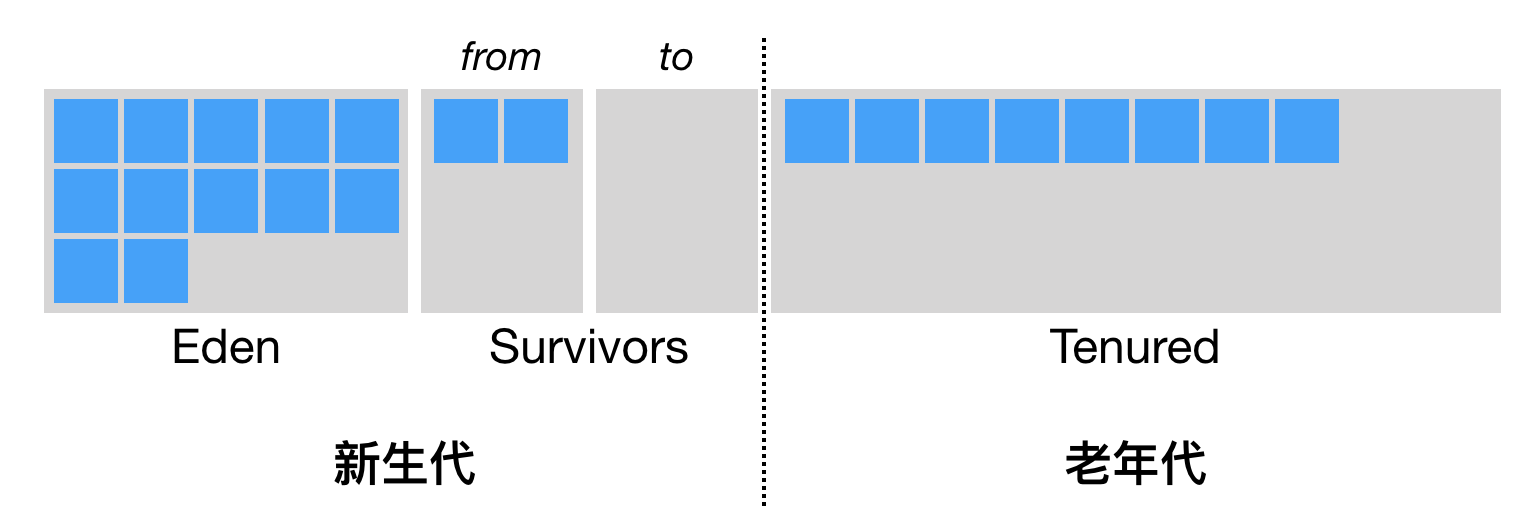
关于怎么判断一个对象是否存活,一开始使用的引用计数,由于对于循环引用无法区分,维护引用计数增加额外开销带来性能问题所以现在已经不在使用了,现在采用可达性分析一个对象是否有路径可以到达GCroot.
stop the world, java虚拟机会在开始进行gc的时候,暂停非GC的线程,如果能分析到这些线程不会跳出安全码以外,那么这些线程还是可以继续运行
- Serial 串行新生代收集器,单线程执行,采用复制算法.
- Serial Old 串行老年代收集器,单线程执行,采用标记整理算法
- ParNew 并行新生代收集器,多线程执行,采用复制算法
- Parallel Scavenge 并行新生代收集器,多线程执行,采用复制算法,可以控制吞吐量
- Parallel Old 并行老年代收集器算法,采用标记整理算法.
- CMS 并行的标记清理算法,由于只清理没有整理所以速度快,但是会产生内存碎片.如果导致内存分配不足会触发fullGC,然后进行内存整理
- G1 将堆内存分成相同大小的Region,而每个region可以单独进行回收,可以在两个region之间进行复制,所以属于标记整理算法,G1名字的由来是先收集垃圾对象特别多得region
类加载
类加载器就是从编译好的class文件,或者从网络中获取字节流,加载到java虚拟机,成为类或者接口.而java中的基本类型是在虚拟机预先定义好的,而引用类型又分为,数组,接口,类和泛型参数.jvm提供了系统类加载器,扩展类加载器,应用加载器,遵循双亲委派机制分别加载自己对应的类.当然也支持自定义类加载器来破坏双亲委派模型,当然不建议这么做,自己实现类加载器的时候一般不要重载loadClass方法,这个方法里面做了双亲委派,一般覆盖findclass方法来实现获取字节码,jvm将类加载分为以下三个过程.
加载
从指定的位置,jar包,文件,网络,手工生成,其他字节码工具的方式获取字节码.
链接
验证阶段,确保被加载的类满足java虚拟机的约束
准备阶段,为被加载的类的静态字段分配内存
解析阶段 将符合引用转换成实际引用,如果被引用的类没有被加载将触发这个类的加载
初始化
如果静态字段是final修饰的,并且这个字段是字符串或者基本类型,那么将会标记为常量值,由虚拟机直接初始化,其他静态变量的赋值以及静态代码块将会统一放到cinit方法内,在满足以下条件的时候会触发调用cinit方法,遇到main启动类,new一个对象,静态方法或者静态属性被调用,反射调用,子类初始化会触发父类初始化
ContextClassLoader
contextClassLoader是thread类里的一个字段,作为上下文类加载器,这个类加载器会从父线程继承过来,也就是创建了该线程的线程,所以默认情况下这个类加载器就应该是AppClassLoader,如果我们业务上需要进行隔离,比如业务A和业务B,他们会共用一些类,但是业务上不想他们互相有依赖,需要完全隔离,那么就可以业务A使用一个线程池,业务B也使用一个线程池,然后分别在线程工厂里设置不同的contextclassloader.这样两个业务用到的虽然是相同的类,但其实是属于不同加载器加载的,所以本质上不同.
钻石依赖

如图,当同时依赖一个jar包的两个不同版本的时候,为了不产生冲突包我们可以用不同的classloader来分别加载这两个用冲突的jar,当然我们可以研究下蚂蚁开源的sofa-ark.
sofaark利用一个plugin将如图相互依赖的,B和D-v0 打成一个fatjar,然后把C和D-v1打成一个fatjar,然后分别用不同的类加载器进行加载.配置在plugin里面,怎么打包是用得springboot里面的打包技术.
jvm提供了javaagent来让jvm启动main方法之前执行premain方法,只需要premain所在的类地址放在所在jar包的MAINFEST.MF文件中,然后在启动参数中加入 -javaagent jar包所在路径
package org.example;
import java.lang.instrument.*;
import java.security.ProtectionDomain;
import org.objectweb.asm.*;
import org.objectweb.asm.tree.*;
public class MyAgent {
public static void premain(String args, Instrumentation instrumentation) {
instrumentation.addTransformer(new MyTransformer());
}
static class MyTransformer implements ClassFileTransformer, Opcodes {
public byte[] transform(ClassLoader loader, String className, Class<?> classBeingRedefined,
ProtectionDomain protectionDomain, byte[] classfileBuffer) throws IllegalClassFormatException {
ClassReader cr = new ClassReader(classfileBuffer);
ClassNode classNode = new ClassNode(ASM7);
cr.accept(classNode, ClassReader.SKIP_FRAMES);
for (MethodNode methodNode : classNode.methods) {
if ("main".equals(methodNode.name)) {
InsnList instrumentation = new InsnList();
instrumentation.add(new FieldInsnNode(GETSTATIC, "java/lang/System", "out", "Ljava/io/PrintStream;"));
instrumentation.add(new LdcInsnNode("Hello, Instrumentation!"));
instrumentation
.add(new MethodInsnNode(INVOKEVIRTUAL, "java/io/PrintStream", "println", "(Ljava/lang/String;)V", false));
methodNode.instructions.insert(instrumentation);
}
}
ClassWriter cw = new ClassWriter(ClassWriter.COMPUTE_FRAMES | ClassWriter.COMPUTE_MAXS);
classNode.accept(cw);
return cw.toByteArray();
}
}
}
有了这个premain方法,我们就可以在jvm加载某一个类的时候做一下增强,例如字节码注入,premain方法参数中可以提供一个instrumentation工具,对字节码进行转换,在做应用监控的时候为了不让应用层依赖监控系统,会采用ASM字节码在需要做拦截的类上做AOP拦截.上面代码演示了找到main方法并在前面加了一个打印语句
调优工具
- jps
打印正在运行的java进程id
- jstat

其中 class 输出类加载的信息,compile输出编译相关数据,其他的都是gc相关,下图可以发现,两个survivor区相等,并且有一个始终为0,
- jmap
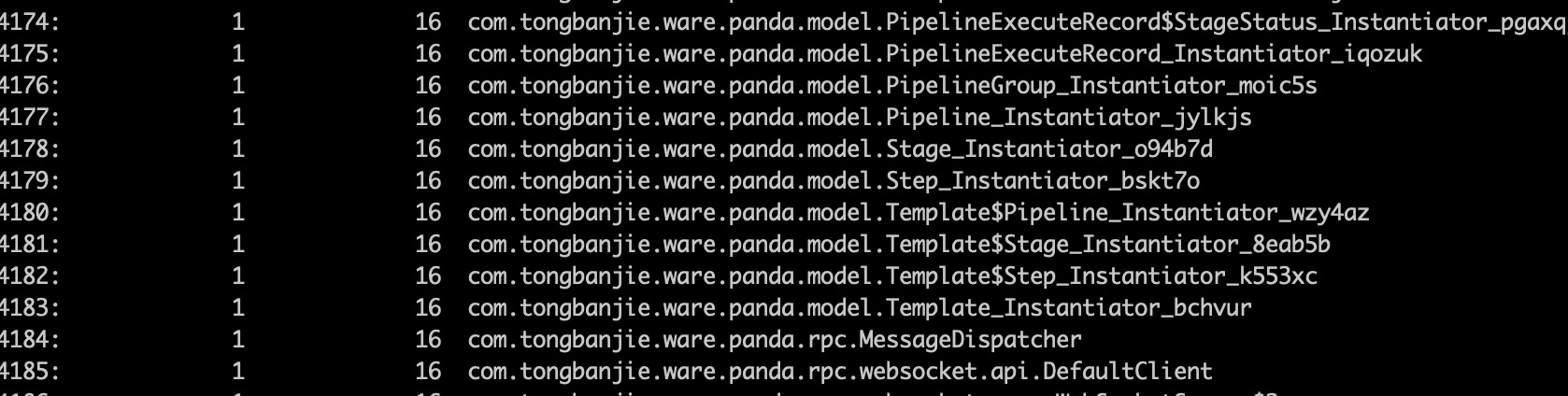
我们一般使用-dump参数导出java虚拟机的堆快照,-live将只打印存活对象,可以用 jmap -histo pid 输出堆中的每个对象的个数和占用的空间,以下可以看出大部分对象都占16个字节
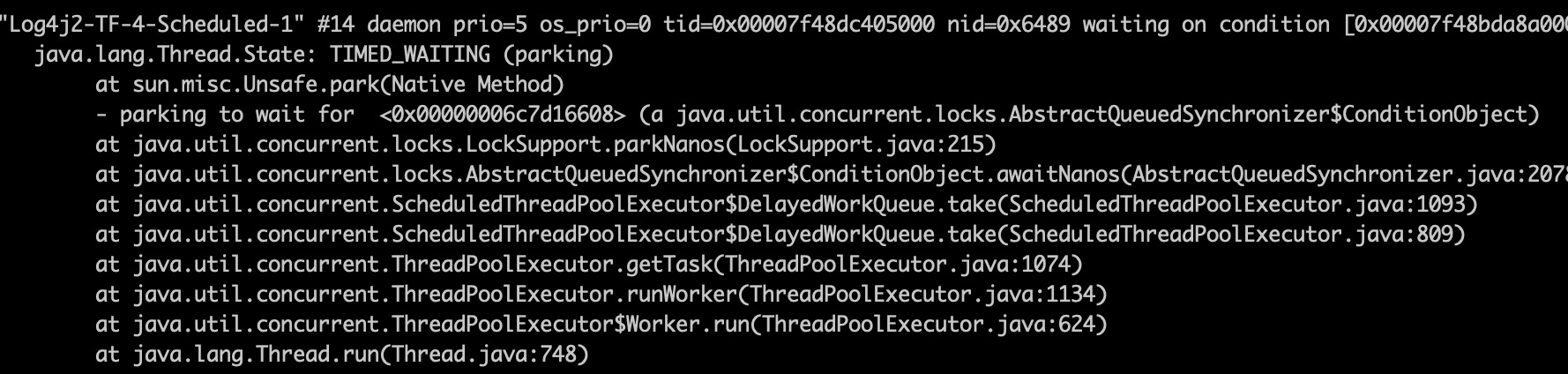
- jstack
jstack看名字就可以发现是打印某个线程的栈轨迹,以及线程间持有的锁,也可以检测死锁,从下图可以看到线程的名字,优先级,以及状态,我们发现该线程的状态是waiting并且是用LockSupport.part阻塞的